原文地址:
The physical structure of records in InnoDB
Record offsets
记录的变长偏移量指针指向记录的起始位置,每一个记录同时也包含一个变长的记录头。在本文中,记录数据的起始位置为N,之后的数据使用正数偏移量(N+1),记录头中使用负数偏移量(N-1)来标示。InnoDB 常以N作为数据记录的起始位置。
The record header
处于数据记录前的记录头结构:
Next Record Offset: 当前页中,指向索引升序顺序中下一个数据记录的相对偏移量
Record Type:记录类型,当前只支持4中类型:
conventional(0) node pointer(1) infimum(2) supremum(3)Order: 记录插入的顺序值。堆记录从0开始计数,Infimum 总是0, supremum总是1, 用户数据从2开始编号。
Numver of Records Owned:在数据页目录本记录占用的记录数
Info Flags: 存储记录布尔标志的4位位图。当前只定义了2个标志:
min_rec(1) 记录为B+tree中非叶节点中的最小值 deleted(2) 删除标记Nullable field bitmap:对每一个可为null的列用一位进行标示是否null,如果某列为null,其列数据将被忽略;如果没有可为null的列,这个标志位将取消。
Variable field lengths array: 由8位或16位整数(根据列的最大值定)组成的数组,记录数据列的长度。如果没有可变长列,此标志位取消。
记录头占每行数据最小到5个字节,如果变长类很多,记录头的长度会大很多。
Clustered indexes
聚集索引记录结构: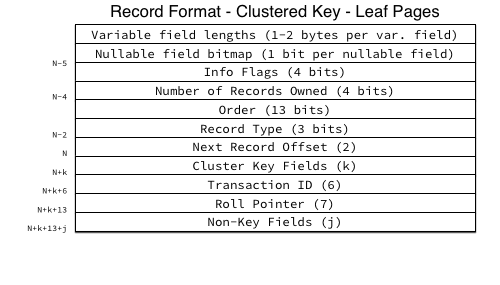
Cluster Key Fields:聚集索引列,串联在一起。InnoDB 使用内部存储引擎对没列的类型原始字节格式化成一个字节流
Transaction ID:48位,上一次更改记录数据的事务ID
Roll Pointer:包含记录了上一次更改记录数据的事务在回滚记录段中的位置信息的结构体。Roll Pointer 结构体包括:
- 1位的‘is insert’标识
- 7位的回滚端ID
- 4位回滚页编号
- 2位回滚页偏移量
None-Key Fields 所有非主键数据,也就是实际的行数据,链接成一个字节流。
非页节点记录结构:
由于非页节点不是MVCC,事务ID和回滚指针都被取消。存在实际数据的列改为存放子节点的指针。由于聚集索引不能为NULL,null标识位也被取消。
Secondary indexes
InnoDB的二级索引和聚集索引的结构一样,只是在聚集索引存放非键值列(叶节点)的空间,二级索引存放的是主键信息(PKV,主键值)。如果二级索引和主键出现重复的列,二级索引中只存放非重复的部分。例如,表的主键为(a,b,c),二级索引为(a,d),则二级索引中存放(a,d),则PKVs中存放(b,c).
由于二级索引的列允许非唯一和可为空,则可变长段和null标识位都可能有值。所以页节点的结构很简单:
同聚集索引一样,二级索引中的这些段连接成一个字节流。
非叶节点的结构:

二级索引的非叶节点有一点需要注意:记录中包含了主键值(PKV),并作为键值的一部分。二级索引允许为非唯一和可为空,则每一个记录都需要一个唯一标识,所以使用主键值来确保唯一性。这意味着二级索引中的非叶节点占用空间比他们的页节点大4个字节。
空间开销
从上面的结构图,很容易计算出InnoDB每一行的空间占用。聚集索引叶节点需要最小5字节的记录头,6字节的事务ID,7字节的回滚指针,每行一共18字节。对于比较小的表,比如只有2-3列整数列,空间浪费比例很大。
另外,在每一页的空间额外开销比例也很大,主要消耗在需要大量空间的无效页的填充上。